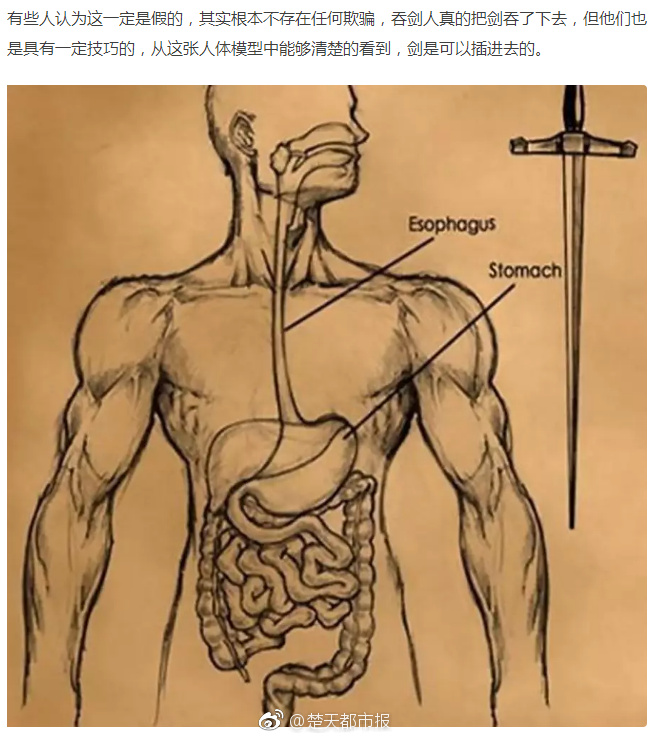
核心内容摘要
人工智能在修辞学中的应用九球直播app下载是一款专门为安卓用户打造的手机应用商城,它可以为用户提供大量的软件资源,而且里面的软件都可以免费下载使用。该软件可以让用户体验更加丰富的手机生活,提供了丰富的应用程序和游戏,为用户推荐更多好用的软件,非常适合安卓手机用户使用。App Store提供了丰富的软件、游戏推荐、排行和新品展示,用户可以在精品、推荐中找到适合自己的应用。同时,App Store还提供搜索功能,用户可以通过关键字搜索到自己需要的应用。





九球直播app下载
为您提供最新院线电影、VIP付费影片的免费在线观看服务,无需开通会员即可畅享海量高清内容,覆盖国内外热门影视剧,更新速度快,资源稳定可靠,是您省心省力的观影好帮手。
芯片散热技术的发展与先进冷却方案
1. 分布式ID的需求与挑战
在分布式系统中,需要一个全局唯一的ID标识不同实体(订单、用户、消息)。挑战:全局唯一(任何节点生成的ID不重复)、趋势递增(便于数据库索引)、高可用(ID生成不能成为瓶颈)、低延迟(毫秒级生成)。UUID(随机生成)全局唯一但无序,数据库插入性能差。自增ID在分布式下无法保证唯一。分布式ID生成器是微服务架构的基础组件。
2. 雪花算法Snowflake详解
Snowflake是Twitter开源的分布式ID生成算法,64位整数:1位符号位(0)+41位时间戳(毫秒级,可用69年)+5位数据中心ID+5位工作机器ID+12位序列号(每毫秒最多4096个ID)。特点:趋势递增(基于时间)、高性能(毫秒级生成百万ID)、无需网络通信。时钟回拨问题:如果服务器时钟回拨,可能生成重复ID。解决方案:记录上次时间戳,如果当前时间小于上次,等待或抛出异常。优化方案:增加逻辑时钟或使用Zookeeper协调时钟。
3. 其他ID生成方案与选型
数据库自增ID + 分段缓存(Leaf):从数据库批量获取ID段缓存在本地,减少数据库压力。优点:简单可靠;缺点:依赖数据库。Zookeeper顺序节点:利用ZK的顺序节点生成递增ID,但性能较低。Redis自增:用Redis的INCR命令生成ID,高性能但依赖Redis。UUID:128位,全局唯一但无序,适合无索引的场景(如事件ID)。MongoDB ObjectId:12字节,含时间戳、机器ID、进程ID、计数器。选型:高性能需求用Snowflake(或改良版本),简单场景用数据库分段,无需排序用UUID。Leaf(美团)是Snowflake + 双Buffer的工业级实现,推荐参考。
SEO与客户旅程管理
1. 大语言模型是什么?
大型语言模型(LLM)是基于深度学习的模型,通过海量文本训练,具备理解和生成人类语言的能力。LLM的核心是Transformer架构,使用自注意力机制捕捉文本中任意位置词之间的关系。模型参数规模从数亿到数万亿(GPT-4估计1.8万亿参数)。训练分为两个阶段:预训练(在大规模公开文本上学习语言基础,无监督)和微调(在特定任务数据上精调,或有监督)。LLM是"统计学习的语言模型",通过预测下一个词实现文本生成。
2. Transformer架构的核心
Transformer由编码器(Encoder)和解码器(Decoder)组成,或仅用编码器(BERT)或仅用解码器(GPT)。自注意力机制(Self-Attention):每个词计算与句子中所有词的相关性,捕获长距离依赖。多头注意力(Multi-Head Attention):多个注意力头并行,从不同角度理解关系。位置编码(Positional Encoding):为词序信息编码,因为Transformer没有RNN的序列结构。前馈网络(FFN):对每个位置独立做非线性变换。残差连接和层归一化帮助训练深层网络。Transformer的成功在于并行计算和长期依赖捕获能力。
3. 预训练和微调的两阶段训练
预训练阶段:模型在互联网规模的数据(网页、书籍、论文、代码)上进行自监督学习。训练目标:掩码语言模型(MLM,预测被遮挡的词,如BERT)或因果语言模型(CLM,预测下一个词,如GPT)。预训练需要数千个GPU、数周甚至数月时间,成本数千万美元。微调阶段:在特定任务数据上精调模型(分类、问答、摘要)。指令微调(Instruction Tuning)让模型学会遵循人类指令;RLHF(基于人类反馈的强化学习)让模型输出更符合人类偏好。GPT-3.5/ChatGPT是在GPT-3基础上经过指令微调和RLHF得到的。
4. 涌现能力和局限性
当模型规模突破某一临界点(约100亿参数),LLM展现出"涌现能力":小模型没有的能力突然出现,如上下文学习(仅凭几个示例就能完成新任务)、推理能力、代码生成等。涌现能力的原因尚不完全清楚,可能与模型在训练中学会了更抽象的表示有关。局限性:幻觉(生成看似合理但错误的信息)、推理能力有限(复杂逻辑和多步推理不稳定)、事实性不一致(训练数据截止后的新知识不知)、计算资源昂贵(推理成本高)。LLM是"随机鹦鹉"(模式匹配)还是真正理解,学术界存在争议。
5. 开源LLM和未来方向
开源LLM:LLaMA(Meta)、Falcon、Mistral、Qwen(阿里)等开源模型,让中小企业和研究者可以本地部署和微调,无需依赖闭源API。开源模型性能逐步逼近闭源GPT-4,降低了AI应用门槛。多模态LLM:GPT-4V、Gemini、Qwen-VL能同时理解文本和图像。Agent框架:LLM作为"大脑",调用工具、执行代码、自主完成任务(AutoGPT、LangChain)。长远趋势:LLM从"聊天工具"进化为"通用智能体",推动AGI(通用人工智能)的探索。LLM是AI领域的范式革命,影响将远超出文字处理。
工业称重传感器:动态特性与抗扰度SEO
〖One〗、电力直流屏SEO需强调“稳压精度、电池深度监测与维护逻辑”。
〖Two〗、详细解析直流电源在负载突变下的输出电压稳定性、蓄电池在线容量检测预警算法及系统对电力控制保护设备的持续供电保障技术。
〖Three〗、案例:某品牌分享的“变电站直流屏应急供电与电池全在线预警技术”,为电力运维团队提供了极佳的安全保障思路,带动了维保续约。
〖Four〗、策略:部署直流电源在线状态预警知识库,展示不同蓄电池容量下的应急维持时间参数,辅助电力设备采购商评估安全可靠性。
〖Five〗、工具:深挖运维人员关于“直流屏电压波动”、“电池组内阻在线监测”、“电力控制直流电源故障”的长尾技术诊断疑问词。
〖Six〗、意图:为电力变电站、大型数据中心提供高稳定性、高预防能力的直流电源系统,确立品牌在电力安全设施领域的专业壁垒。
商用烤箱:受热均匀度与热效率曲线分析SEO
〖One〗、工业高压清洗设备SEO核心:在于“喷嘴流体力学设计与压力流速的高效耦合”。
〖Two〗、技术剖析:探讨高压水射流去除油脂的冲刷机理,分析压力与流量对效率的非线性关系,以及如何根据工件材质选择最佳压力以防损伤。
〖Three〗、价值体现:发布“重工业清洗效率与能耗对比”,通过实测数据展现高效喷射技术在减少清洗时间方面的表现。
〖Four〗、工程选型:构建清洗方案指南,涵盖压力等级选择与路径优化,辅助维保工程师提升作业效率。
〖Five〗、长尾痛点监测:监测“高压清洗压力不足”、“喷嘴磨损对效率影响”、“工业清洗水垢处理”等相关长尾词。
〖Six〗、意图:向重工业、能源行业提供清洗彻底、能耗极低、设备故障率小的整体工业高压清洗方案。
商业级厨房设备与冷链制冷系统B2B出口大纲
〖One〗、工业红外热成像核心:在于辐射率修正算法对复杂材质表面温测的精度提升。
〖Two〗、深度解析:解析在金属、塑料等不同反射率表面下如何通过修正参数实现真实测温,探讨红外成像隐患筛查模型的构建。
〖Three〗、应用:展示工业高压电气配电柜的预防性热成像检修应用。
〖Four〗、意图:为制造工厂、能源站提供隐患早期发现、测温精确的工业红外监测方案。
优化核心要点
人工智能在食品工程中的应用九球直播app下载工业无线传感数据采集:可靠性与抗干扰SEO